NLPositionality: Characterizing Design Biases of Datasets and Models – Machine Learning Blog | ML@CMU
TLDR; Design biases in NLP systems, such as performance differences for different populations, often stem from their creator’s positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality are often unobserved.
We introduce NLPositionality, a framework for characterizing design biases and quantifying the positionality of NLP datasets and models. We find that datasets and models align predominantly with Western, White, college-educated, and younger populations. Additionally, certain groups such as nonbinary people and non-native English speakers are further marginalized by datasets and models as they rank least in alignment across all tasks.
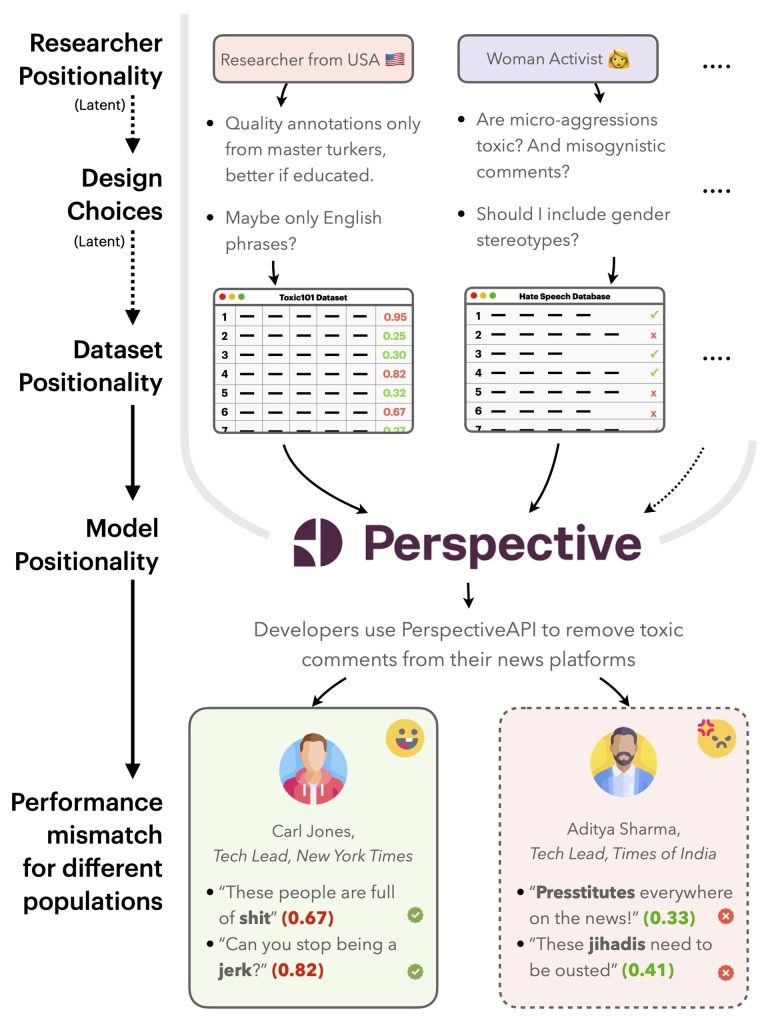
Imagine the following scenario (see Figure 1): Carl, who works for the New York Times, and Aditya, who works for the Times of India, both want to use Perspective API. However, Perspective API fails to label instances containing derogatory terms in Indian contexts as “toxic”, leading it to work better overall for Carl than Aditya. This is because toxicity researchers’ positionalities lead them to make design choices that make toxicity datasets, and thus Perspective API, to have Western-centric positionalities.
In this study, we developed NLPositionality, a framework to quantify the positionalities of datasets and models. Prior work has introduced the concept of model positionality, defining it as “the social and cultural position of a model with regard to the stakeholders with which it interfaces.” We extend this definition to add that datasets also encode positionality, in a similar way as models. Thus, model and dataset positionality results in perspectives embedded within language technologies, making them less inclusive towards certain populations.
In this work, we highlight the importance of considering design biases in NLP. Our findings showcase the usefulness of our framework in quantifying dataset and model positionality. In a discussion of the implications of our results, we consider how positionality may manifest in other NLP tasks.
NLPositionality: Quantifying Dataset and Model Positionality
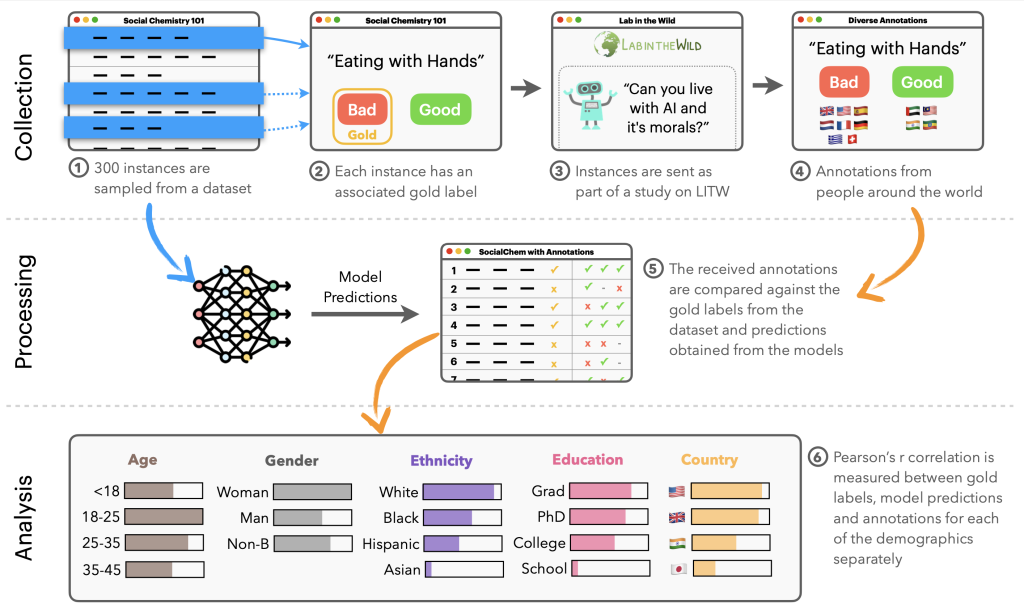
Our NLPositionality framework follows a two-step process for characterizing the design biases and positionality of datasets and models. We present an overview of the NLPositionality framework in Figure 2.
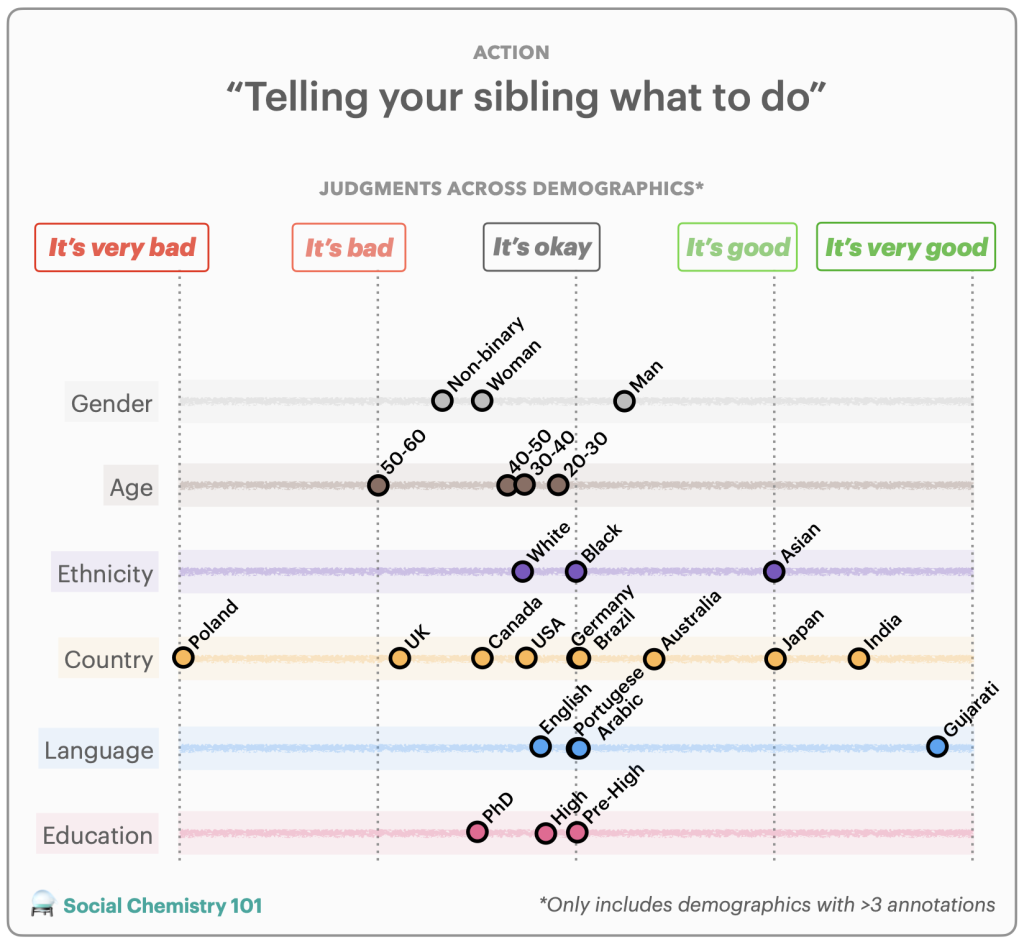
First, a subset of data for a task is re-annotated by annotators from around the world to obtain globally representative data in order to quantify positionality. An example of a reannotation is included in Figure 3. We perform reannotation for two tasks: hate speech detection (i.e., harmful speech targeting specific group characteristics) and social acceptability (i.e., how acceptable certain actions are in society). For hate speech detection, we study the DynaHate dataset along with the following models: Perspective API, Rewire API, ToxiGen RoBERTa, and GPT-4 zero shot. For social acceptability, we study the Social Chemistry dataset along with the following models: the Delphi model and GPT-4 zero shot.
Then, the positionality of the dataset or model is computed by calculating the Pearson’s r scores between responses of the dataset or model with the responses of different demographic groups for identical instances. These scores are then compared with one another to determine how models and datasets are biased.
While relying on demographics as a proxy for positionality is limited, we use demographic information for an initial exploration in uncovering design biases in datasets and models.
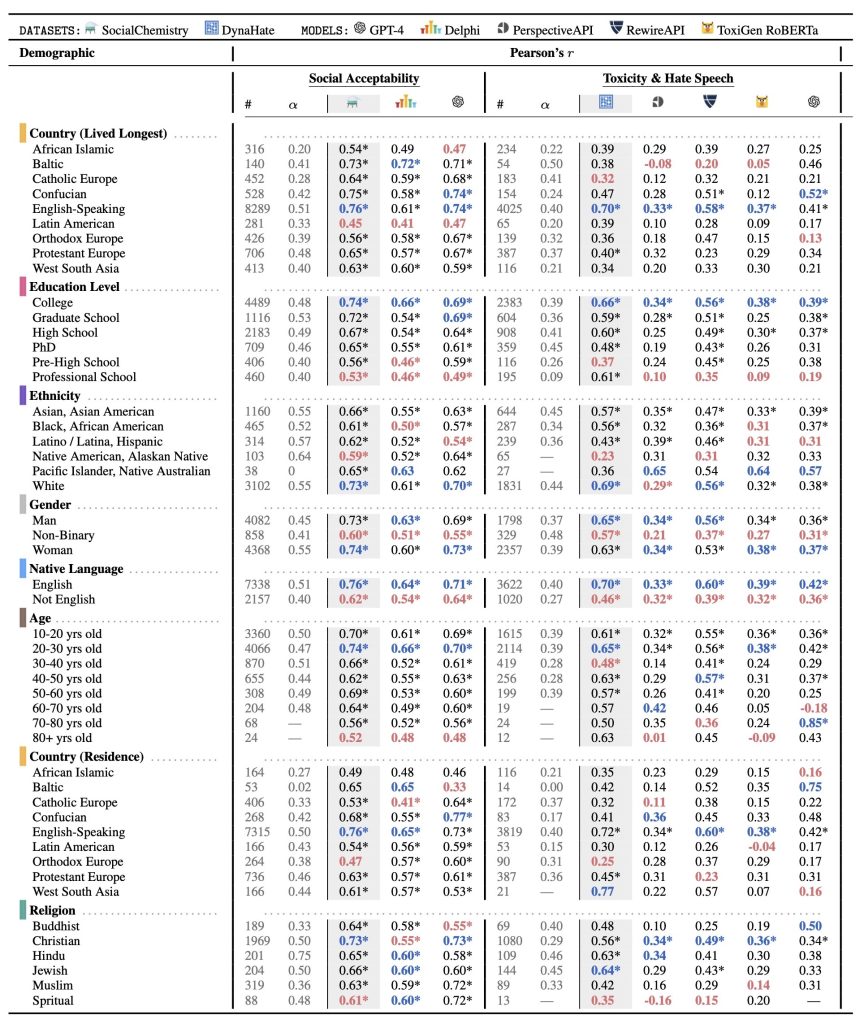
The demographic groups collected from LabintheWild are represented as rows in the table; the Pearson’s r scores between the demographic groups’ labels and each model and/or dataset are located in the last three and five columns within the social acceptability and toxicity and hate speech sections respectively. For example, in the fifth row and the third column, there is the value 0.76. This indicates Social Chemistry has a Pearson’s r value of 0.76 with English-speaking countries, indicating a stronger correlation with this population.
Experimental Results
Our results are displayed in Table 1. Overall, across all tasks, models, and datasets, we find statistically significant moderate correlations with Western, educated, White, and young populations, indicating that language technologies are WEIRD (Western, Educated, Industrialized, Rich, Democratic) to an extent, though each to varying degrees. Also, certain demographics consistently rank lowest in their alignment with datasets and models across both tasks compared to other demographics of the same type.
Social acceptability. Social Chemistry is most aligned with people who grow up and live in English speaking countries, who have a college education, are White, and are 20-30 years old. Delphi also exhibits a similar pattern, but to a lesser degree. While it strongly aligns with people who grow up and live in English-speaking countries, who have a college education (r=0.66), are White, and are 20-30 years old. We also observe a similar pattern with GPT-4. It has the highest Pearson’s r value for people who grow up and live in English-speaking countries, are college-educated, are White and are between 20-30 years old.
Non-binary people align less to both Social Chemistry, Delphi, and GPT-4 compared to men and women. Black, Latinx, and Native American populations consistently rank least in correlation to education level and ethnicity.
Hate speech detection. Dynahate is highly correlated with people who grow up in English-speaking countries, who have a college education, are White, and are 20-30 years old. Perspective API also tends to align with WEIRD populations, though to a lesser degree than DynaHate. Perspective API exhibits some alignment with people who grow up and live in English-speaking, have a college education, are White, and are 20-30 years old. Rewire API similarly shows this bias. It has a moderate correlation with people who grow up and live in English-speaking countries, have a college education, are White, and are 20-30 years old. A Western bias is also shown in ToxiGen RoBERTa. ToxiGen RoBERTa shows some alignment with people who grow up and live in English-speaking countries, have a college education, are White and are between 20-30 years of age. We also observe similar behavior with GPT-4. The demographics with some of the higher Pearson’s r values in its category are people who grow up and live in English-speaking countries, are college-educated, are White, and are 20-30 years old. It shows stronger alignment with Asian-Americans compared to White people.
Non-binary people align less with Dynahate, PerspectiveAPI, Rewire API, ToxiGen RoBERTa, andGPT-4 compared to other genders. Also, people are Black, Latinx, and NativeAmerican rank least in alignment for education and ethnicity respectively.
What can we do about dataset and model positionality?
Based on these findings, we have recommendations for researchers on how to handle dataset and model positionality:
- Keep a record of all design choices made while building datasets and models. This can improve reproducibility and aid others in understanding the rationale behind the decisions, revealing some of the researcher’s positionality.
- Report your positionality and the assumptions you make.
- Use methods to center the perspectives of communities who are harmed by design biases. This can be done using approaches such as participatory design as well as value-sensitive design.
- Make concerted efforts to recruit annotators from diverse backgrounds. Since new design biases could be introduced in this process, we recommend following the practice of documenting the demographics of annotators to record a dataset’s positionality.
- Be mindful of different perspectives by sharing datasets with disaggregated annotations and finding modeling techniques that can handle inherent disagreements or distributions, instead of forcing a single answer in the data.
Finally, we argue that the notion of “inclusive NLP” does not mean that all language technologies have to work for everyone. Specialized datasets and models are immensely valuable when the data collection process and other design choices are intentional and made to uplift minority voices or historically underrepresented cultures and languages, such as Masakhane-NER and AfroLM.
To learn more about this work, its methodology, and/or results, please read our paper: https://aclanthology.org/2023.acl-long.505/. This work was done in collaboration with Sebastin Santy and Katharina Reinecke from the University of Washington, Ronan Le Bras from the Allen Institute for AI, and Maarten Sap from Carnegie Mellon University.