Rethinking the Role of PPO in RLHF – The Berkeley Artificial Intelligence Research Blog
Rethinking the Role of PPO in RLHF TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human
Continue reading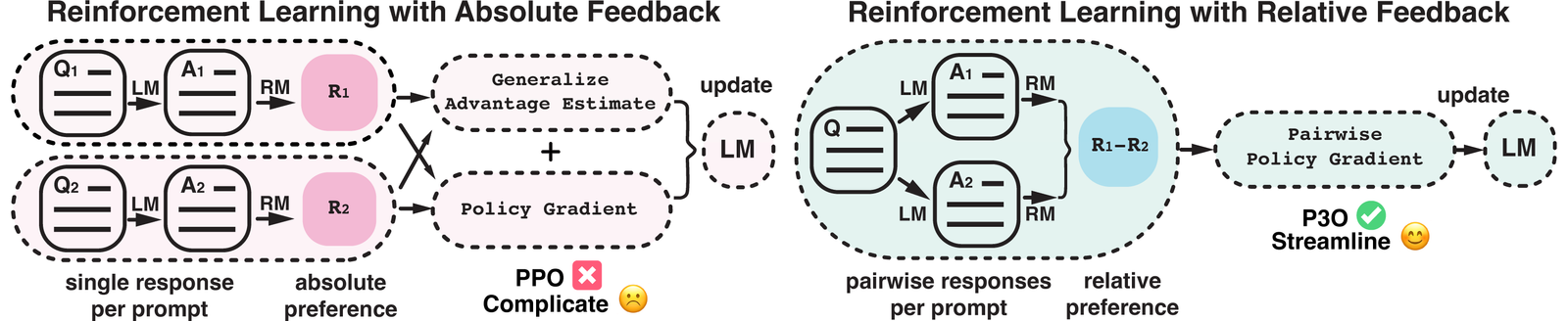
Rethinking the Role of PPO in RLHF TL;DR: In RLHF, there’s tension between the reward learning phase, which uses human
Continue readingTraining Diffusion Models with Reinforcement Learning replay Diffusion models have recently emerged as the de facto standard for generating complex,
Continue reading