Image by Author
Over the recent year and a half, the landscape of natural language processing (NLP) has seen a remarkable evolution, mostly thanks to the rise of Large Language Models (LLMs) like OpenAI’s GPT family.
These powerful models have revolutionized our approach to handling natural language tasks, offering unprecedented capabilities in translation, sentiment analysis, and automated text generation. Their ability to understand and generate human-like text has opened up possibilities once thought unattainable.
However, despite their impressive capabilities, the journey to train these models is full of challenges, such as the significant time and financial investments required.
This brings us to the critical role of fine-tuning LLMs.
By refining these pre-trained models to better suit specific applications or domains, we can significantly enhance their performance on particular tasks. This step not only elevates their quality but also extends their utility across a wide array of sectors.
This guide aims to break down this process into 7 simple steps to get any LLM fine-tuned for a specific task.
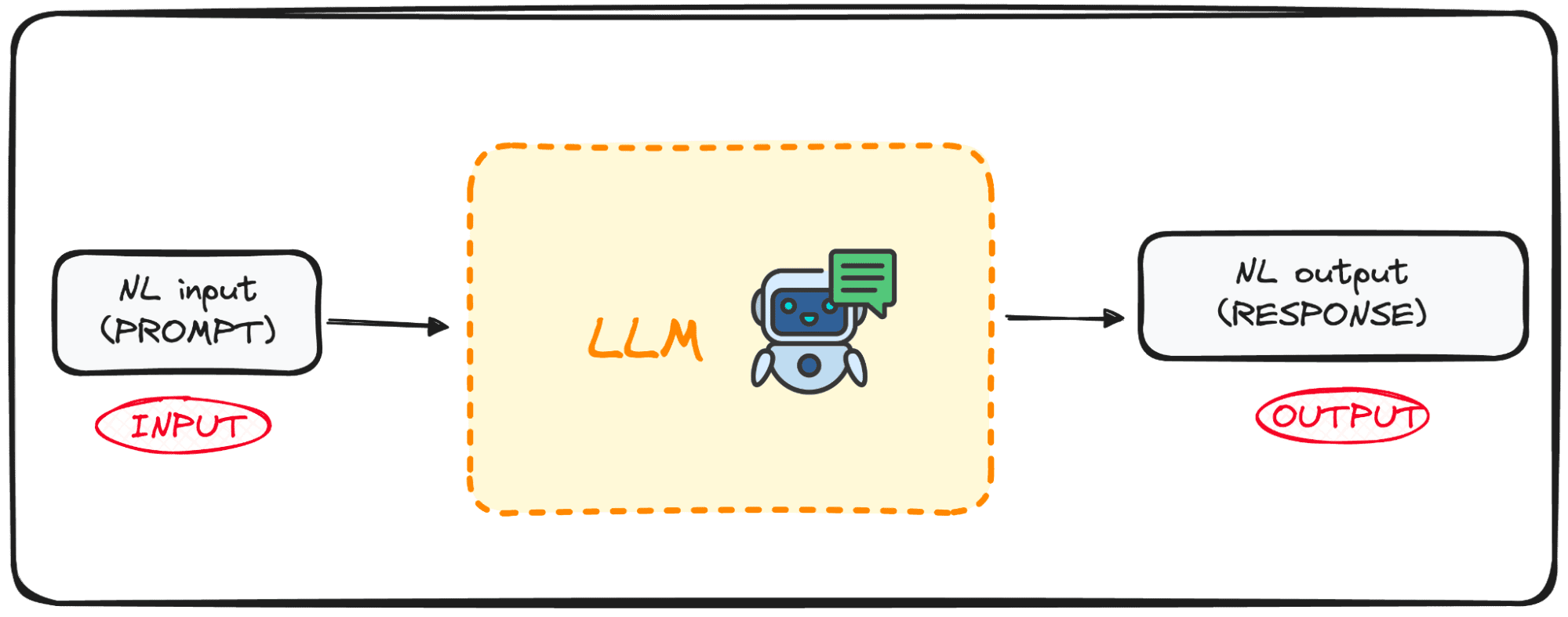
LLMs are a specialized category of ML algorithms designed to predict the next word in a sequence based on the context provided by the preceding words. These models are built upon the Transformers architecture, a breakthrough in machine learning techniques and first explained in Google’s All you need is attention article.
Models like GPT (Generative Pre-trained Transformer) are examples of pre-trained language models that have been exposed to large volumes of textual data. This extensive training allows them to capture the underlying rules of language usage, including how words are combined to form coherent sentences.

Image by Author
A key strength of these models lies in their ability to not only understand natural language but also to produce text that closely mimics human writing based on the inputs they are given.
So what’s the best of this?
These models are already open to the masses using APIs.
What is Fine-tuning, and Why is it Important?
Fine-tuning is the process of picking a pre-trained model and improving it with further training on a domain-specific dataset.
Most LLM models have very good natural language skills and generic knowledge performance but fail in specific task-oriented problems. The fine-tuning process offers an approach to improve model performance for specific problems while lowering computation expenses without the necessity of building them from the ground up.
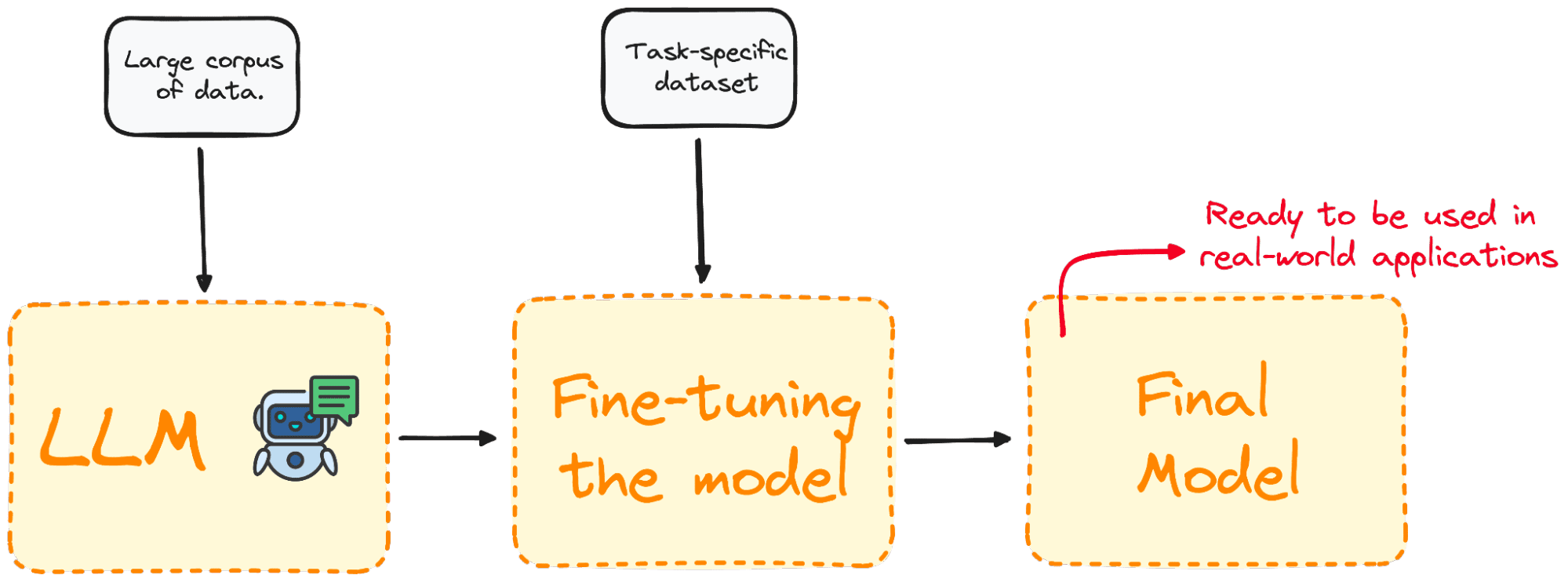
Image by Author
To put it simply, Fine-tuning tailors the model to have a better performance for specific tasks, making it more effective and versatile in real-world applications. This process is essential for improving an existing model for a particular task or domain.
Let’s exemplify this concept by fine-tuning a real model in only 7 steps.
Step 1: Having our concrete objective clear
Imagine we want to infer the sentiment of any text and decide to try GPT-2 for such a task.
I’m pretty sure there’s no surprise that we will soon enough detect it is quite bad at doing so. Then, one natural question that comes to mind is:
Can we do something to improve its performance?
And of course, the answer is that we can!
Taking advantage of fine-tuning by training our pre-trained GPT-2 model from the Hugging Face Hub with a dataset containing tweets and their corresponding sentiments so the performance improves.
So our ultimate goal is to have a model that is good at inferring the sentiment out of text.
Step 2: Choose a pre-trained model and a dataset
The second step is to pick what model to take as a base model. In our case, we already picked the model: GPT-2. So we are going to perform some simple fine-tuning to it.
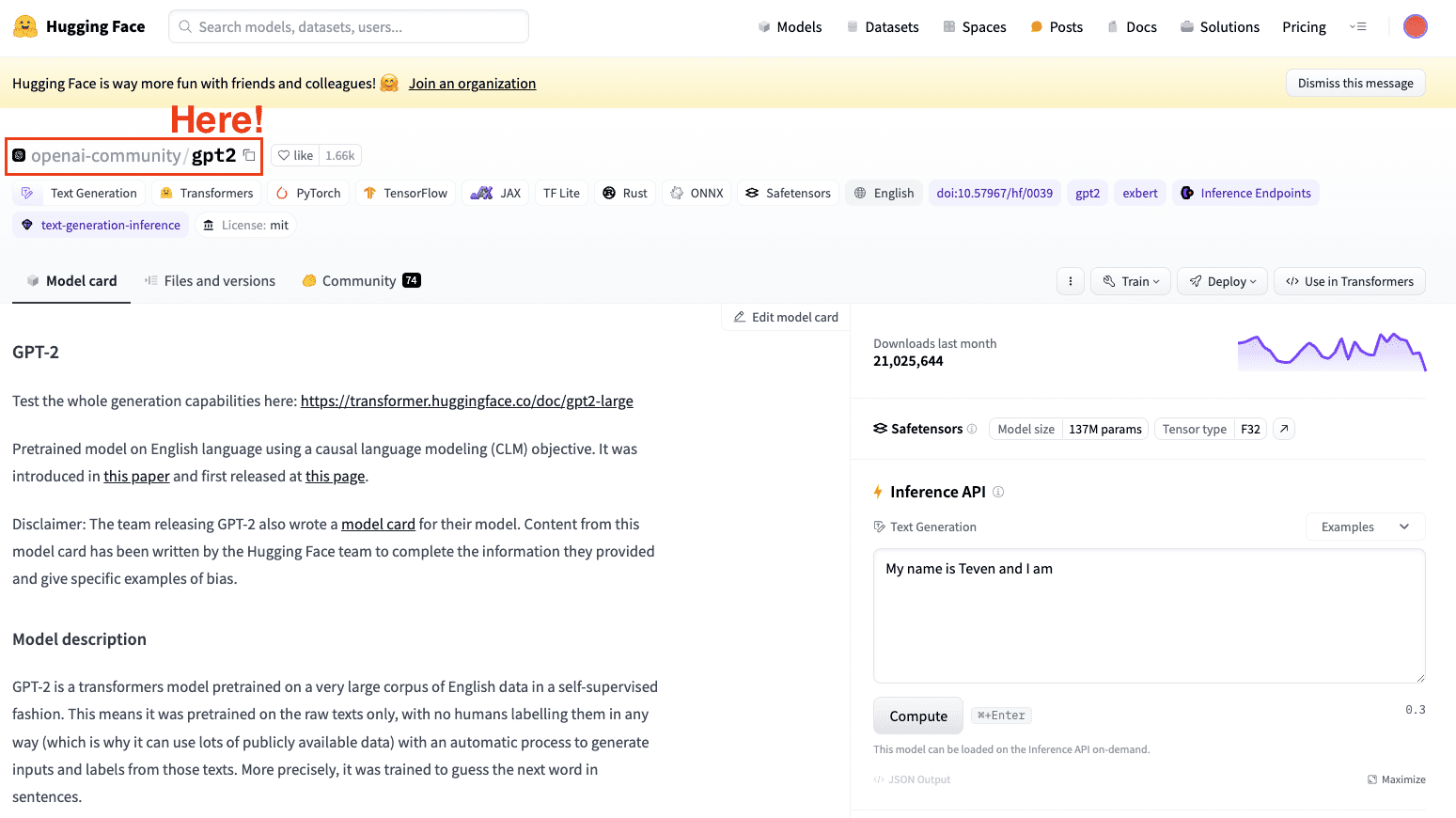
Screenshot of Hugging Face Datasets Hub. Selecting OpenAI’s GPT2 model.
Always keep in mind to select a model that fits your task.
Step 3: Load the data to use
Now that we have both our model and our main task, we need some data to work with.
But no worries, Hugging Face has everything arranged!
This is where their dataset library kicks in.
In this example, we will take advantage of the Hugging Face dataset library to import a dataset with tweets labeled with their corresponding sentiment (Positive, Neutral or Negative).
from datasets import load_dataset
dataset = load_dataset("mteb/tweet_sentiment_extraction")
df = pd.DataFrame(dataset['train'])
The data looks like follows:

The data set to be used.
Step 4: Tokenizer
Now we have both our model and the dataset to fine-tune it. So the following natural step is to load a tokenizer. As LLMs work with tokens (and not with words!!), we require a tokenizer to send the data to our model.
We can easily perform this by taking advantage of the map method to tokenize the whole dataset.
from transformers import GPT2Tokenizer
# Loading the dataset to train our model
dataset = load_dataset("mteb/tweet_sentiment_extraction")
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
tokenizer.pad_token = tokenizer.eos_token
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
BONUS: To improve our processing performance, two smaller subsets are generated:
- The training set: To fine-tune our model.
- The testing set: To evaluate it.
small_train_dataset = tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset = tokenized_datasets["test"].shuffle(seed=42).select(range(1000))
Step 5: Initialize our base model
Once we have the dataset to be used, we load our model and specify the number of expected labels. From the Tweet’s sentiment dataset, you can know there are three possible labels:
- 0 or Negative
- 1 or Neutral
- 2 or Positive
from transformers import GPT2ForSequenceClassification
model = GPT2ForSequenceClassification.from_pretrained("gpt2", num_labels=3)
Step 6: Evaluate method
The Transformers library provides a class called “Trainer” that optimizes both the training and the evaluation of our model. Therefore, before the actual training is begun, we need to define a function to evaluate the fine-tuned model.
import evaluate
metric = evaluate.load("accuracy")
def compute_metrics(eval_pred):
logits, labels = eval_pred
predictions = np.argmax(logits, axis=-1)
return metric.compute(predictions=predictions, references=labels)
Step 7: Fine-tune using the Trainer Method
The final step is fine-tuning the model. To do so, we set up the training arguments together with the evaluation strategy and execute the Trainer object.
To execute the Trainer object we just use the train() command.
from transformers import TrainingArguments, Trainer
training_args = TrainingArguments(
output_dir="test_trainer",
#evaluation_strategy="epoch",
per_device_train_batch_size=1, # Reduce batch size here
per_device_eval_batch_size=1, # Optionally, reduce for evaluation as well
gradient_accumulation_steps=4
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=small_train_dataset,
eval_dataset=small_eval_dataset,
compute_metrics=compute_metrics,
)
trainer.train()
Once our model has been fine-tuned, we use the test set to evaluate its performance. The trainer object already contains an optimized evaluate() method.
import evaluate
trainer.evaluate()
This is a basic process to perform a fine-tuning of any LLM.
Also, remember that the process of fine-tuning a LLM is highly computationally demanding, so your local computer may not have enough power to perform it.
Today, fine-tuning pre-trained large language models like GPT for specific tasks is crucial to enhancing LLMs performance in specific domains. It allows us to take advantage of their natural language power while improving their efficiency and the potential for customization, making the process accessible and cost-effective.
Following these simple 7 steps —from selecting the right model and dataset to training and evaluating the fine-tuned model— we can achieve a superior model performance in specific domains.
For those who want to check the full code, it is available in my large language models GitHub repo.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is currently working in the data science field applied to human mobility. He is a part-time content creator focused on data science and technology. Josep writes on all things AI, covering the application of the ongoing explosion in the field.