These computer science terms are frequently used synonymously, but what differences make each a special technology?
Every minute technology is becoming more embedded in our daily lives. To meet the increasing expectations of their customers, companies are depending more heavily on machine learning algorithms to simplify processes. Its use is evident in social media (through object detection in photos) or with direct communication with devices (like Alexa or Siri).
While artificial intelligence (AI), machine learning (ML), deep learning, and neural networks are related technologies, the phrases are commonly used interchangeably, which frequently causes confusion regarding their differences.
Difference Between Deep Learning and Machine Learning
Machine learning refers to the study of computer systems that pick up new skills and adjust automatically from experience without explicit programming.
With simple AI, a programmer can teach a machine how to react to a variety of sets of instructions by hand-coding each “decision.” With machine learning models, computer scientists can “instruct” a machine by presenting it with vast amounts of data.
The machine follows a collection of guidelines-called an algorithm-to examine and draw inferences from the data. The more data the machine examines, the more adept it can become at carrying out a task or coming to a conclusion.
For instance, you may be familiar with the music streaming service Spotify gets to know your taste in music to offer you new recommendations. Each time you signify that you like a song by finishing it or adding it to your collection, the service updates its algorithms to provide you with more precise recommendations. Amazon and Netflix use similar machine-learning algorithms to provide personalized recommendations.
Deep learning algorithms can enhance their results through repetition, without human involvement. Whereas machine learning algorithms typically require human correction when they make a mistake. A machine learning algorithm can be built on relatively very small sets of data, but a deep learning algorithm requires vast data sets that may contain heterogeneous and unstructured data.
Consider deep learning as an advancement of machine learning. Deep learning is a machine learning method that develops algorithms and computing units-or neurons-into what is called an artificial neural network. These deep neural networks are inspired by the structure of the human brain. Similar to how our brains process information, data flows through this network of interconnected algorithms in a non-linear manner.
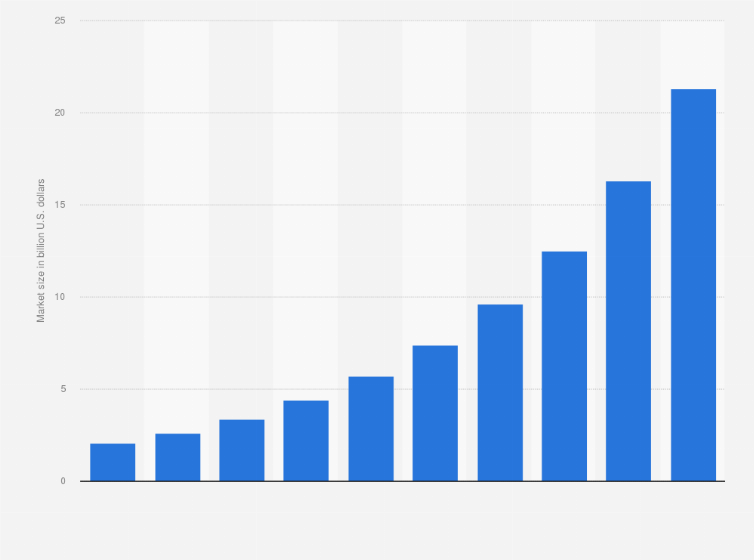
Predictions indicate that the global revenues from the deep learning chip industry will rise from $2.62 billion in 2019 to over $20 billion by 2027. North America is expected to contribute the largest share of this revenue.
Understanding Machine Learning
Machine learning (ML) is a branch of artificial intelligence (AI) that focuses on creating systems that learn-or enhance performance-based on the data they utilize. The phrase artificial intelligence refers to systems or machines that mimic human intelligence. The terms are sometimes used interchangeably, AI and machine learning are often discussed together, but they don’t mean the same thing. It’s crucial to keep in mind that although all machine learning is AI, not all AI is machine learning.
There are three standard machine learning methods:
- Supervised learning: The process of training a model with data that is already labeled, meaning that data scientists know the desired results and can build the machines to arrive at the same conclusions. The machine can automatically make predictions when presented with new, unlabeled, or unknown data after the algorithm learns by studying these examples
- Unsupervised learning: The opposite of supervised learning in that the data is unlabeled and the results are unknown. The machine’s objective is to discover patterns, trends, and similarities in data and group them without knowing the desired outcome.
- Reinforcement learning: Builds an algorithm by giving the machine regular feedback. Poor results are punished while positive outcomes are rewarded, enabling the algorithm to identify certain trends in data and adjust its decision-making approach to improve its performance over time.
Limitations and Challenges of Machine Learning
Machine learning stands at the forefront of technological innovation, offering significant benefits yet facing notable challenges. Key among these are the need for greater transparency and interpretability to ensure understanding and trust in decisions made by AI systems. Additionally, machine learning must address inherent biases and discrimination within data, the technical hurdles of overfitting and underfitting, and the frequent scarcity of necessary data. Paramount, too, are the ethical considerations, where the impact of AI on society and individual rights must be rigorously evaluated. Addressing these challenges is crucial for the responsible advancement of machine learning technologies.
- Lack of Transparency and Interpretability: One of its main challenges is more transparency and interpretability in machine learning. As they don’t disclose how a judgment was made or the process by which a decision was reached, machine learning algorithms are often referred to as “black boxes.” This makes it difficult to understand how a specific model concluded and might be challenging when explanations are required. For example, understanding the logic behind a specific diagnosis in healthcare might be easier with transparency and interpretability.
- Bias and Discrimination: The possibility of prejudice and discrimination is a crucial setback in machine learning. Vast datasets may have data biases and are used to instruct machine learning systems. If these biases are not rectified, the machine learning system may reinforce them, producing biased results. The algorithms utilized in face recognition are one example of bias in machine learning. Research indicates that facial recognition software performs poorly on those with darker skin tones, which leads to false positive and false negative rates being higher for people of different races.
- Overfitting and Underfitting: Overfitting and Underfitting are two issues that machine learning algorithms often face. Overfitting is a process where a machine learning model works poorly on new, unidentified data because it needs to be simplified since it was trained too successfully on the training data. On the other side, underfitting occurs when a machine learning model is overly simplistic and fails to identify the underlying patterns in the data, which leads to subpar performance on both the new data and training data.
- Limited Data Availability: A significant obstacle for machine learning is the requirement for more available data. Machine learning algorithms need a huge amount of data to develop and make reliable predictions. However, there might demand for more data available or only restricted access to it in various sectors. Due to privacy considerations, it might be challenging to obtain medical data, while data from rare events, such as natural catastrophes, may be of restricted scope.
- Ethical Considerations: Machine learning models can have serious social, ethical, and legal repercussions when used to pass judgments that impact people’s lives. Machine learning models, for example, may have a different influence on groups of individuals when used to make employment or determine loans. Privacy, security, and data ownership must also be resolved when adopting machine learning models.
Understanding Deep Learning
Deep learning models can be used for a wide range of activities since they process information similarly to the human brain. they are applicable to numerous tasks that humans perform. Deep learning is currently used in most frequently used image recognition tools, natural language processing (NLP), and speech recognition software.
Deep learning is currently being applied in all types of big data analytics applications, especially those focused on NLP, language translation, stock market trading signals, medical diagnosis, network security, and image recognition.
Specific fields in which deep learning is currently being applied include the following:
- Customer experience (CX): Deep learning models are already being utilized for chatbots. And, as it continues to develop, deep learning is anticipated to be utilized in a variety of businesses to enhance CX and boost customer satisfaction.
- Text generation: After teaching a machine a text’s grammar and style, the machine uses this model to automatically produce a new text that exactly matches the original text’s spelling, grammar, and style.
- Aerospace and military: Deep learning is being applied to detect objects from satellites that identify areas of interest, as well as safe or dangerous zones for troops.
- Industrial Automation: Deep learning is enhancing worker safety in environments like warehouses and factories by enabling services through industrial automation that automatically detects when a worker or object is approaching too close to a machine.
- Adding color: Deep learning models can be used to add color to black-and-white photos and videos. This was an extremely time-consuming, manual procedure, in the past.
- Computer vision: Computer vision has been substantially improved by deep learning, giving computers extremely accurate object detection, and image classification, restoration, and segmentation capabilities.
Limitations and Challenges of Deep Learning
Deep learning systems come with setbacks as well, for instance:
- They learn by observation, which means they only know what was in the data on which they were taught. If a user only has a small amount of data or it comes from a single source that is not necessarily representative of the larger functional area, the models don’t learn in a generalizable way.
- The issue of biases is also a significant challenge for deep learning models. When a model trains on data that contains biases, the model replicates those biases in its predictions. This has been a crucial issue for deep learning programmers as models learn to distinguish based on subtle variations in data elements. Often, the programmer is not given explicit access to the factors it deems significant. This implies that, for instance, a facial recognition model may determine a person’s characteristics based on factors such as race or gender without the programmer being aware.
- The learning rate also becomes a significant problem for deep learning models. If the rate is too high, then the model converges too fast, resulting in a less-than-optimal solution. If the rate is too low, then the process may stall, and it is even difficult to reach a solution.
- Limitations are also caused by the hardware requirements of deep learning models. Multicore high-performing graphics processing units (GPUs) and other related processing units are needed to guarantee increased efficiency and reduce time consumption. However, these units are costly and use huge amounts of energy. Other hardware necessities include RAM and a hard disk drive or RAM-based solid-state drive.
- Requires vast amounts of data. Moreover, the more sophisticated and specific models require more parameters, which, in turn, need more data.
- Lack of multitasking. Once trained, deep learning models become rigid and are unable to multi-task. They can provide efficient and precise solutions but only to one particular problem. Even solving a related issue would require retraining the system.
- Lack of reasoning. Any application that requires reasoning such as applying the scientific approach, programming, long-term planning, and algorithm-like data manipulation is also beyond what current deep learning approaches can do, even with wide amounts of data.
Conclusion
The constant advancement of AI gives new avenues for machine development. Machine learning vs Deep Learning, are regarded to be the subcategories of Artificial intelligence. Both Machine Learning and Deep Learning are unique algorithms that can carry out certain jobs, distinguished by their advantages. While deep learning requires less help due to its basic emulation of the human brain’s workflow and context understanding, machine learning algorithms can analyze and learn from the given data and are prepared to make a final decision with minimal but still assistance from a human assistant. Due to constant advancement, we can refer to deep learning as a subset of machine learning, which is distinguished by self-sufficient decision-making that has allowed wider use and keeps on learning, developing, and succeeding in a variety of tasks.
The post Deep Learning vs. Machine Learning: Understanding the Differences appeared first on Datafloq.