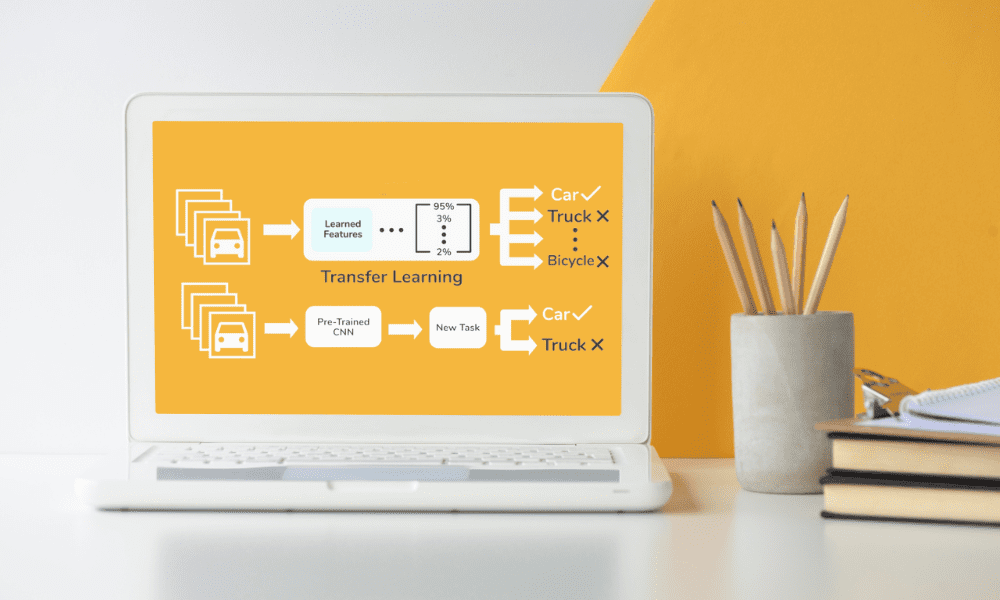
Image by Editor | Transfer Learning Flow from Skyengine.ai
When it comes to machine learning, where the appetite for data is insatiable, not everyone has the luxury of accessing vast datasets to learn from at a whim—that’s where transfer learning comes to the rescue, especially when you’re stuck with limited data or the cost of acquiring more is just too high.
This article is going to take a closer look at the magic of transfer learning, showing how it cleverly uses models that have already learned from massive datasets to give your own machine learning projects a significant boost, even when your data is on the slim side.
I’m going to tackle the hurdles that come with working in data-scarce environments, peek into what the future might hold, and celebrate the versatility and effectiveness of transfer learning across all kinds of different fields.
Transfer learning is a technique used in machine learning that takes a model developed for one task and repurposes it for a second, related task, evolving it further.
At its core, this approach hinges on the idea that knowledge gained while learning one problem can assist in solving another, somewhat similar problem.
For instance, a model trained to recognize objects within images can be adapted to recognize specific types of animals in photos, leveraging its pre-existing knowledge of shapes, textures, and patterns.
It actively accelerates the training process while at the same time also significantly reducing the amount of data that’s required. In small data scenarios, this is particularly beneficial, as it circumvents the traditional need for vast datasets to achieve high model accuracy.
Utilizing pre-trained models lets practitioners bypass many of the initial hurdles that are commonly associated with model development, such as feature selection and model architecture design.
Pre-trained models serve as the true foundation for transfer learning, and these models, often developed and trained on large-scale datasets by research institutions or tech giants, are made available for public use.
The versatility of pre-trained models is remarkable, with applications ranging from image and speech recognition to natural language processing. Adopting these models for new tasks can drastically cut down on development time and the resources you need.
For example, models trained on the ImageNet database, which contains millions of labeled images across thousands of categories, provide a rich feature set for a wide range of image recognition tasks.
The adaptability of these models to new, smaller datasets underscores their value, allowing for the extraction of complex features without the need for extensive computational resources.
Working with limited data presents unique challenges—the primary concern is overfitting, where a model learns the training data too well, including its noise and outliers, leading to poor performance on unseen data.
Transfer learning mitigates this risk by using models pre-trained on diverse datasets, thereby enhancing generalization.
However, the effectiveness of transfer learning depends on the relevance of the pre-trained model to the new task. If the tasks involved are too dissimilar, then the benefits of transfer learning may not fully materialize.
Moreover, fine-tuning a pre-trained model with a small dataset requires careful adjustment of parameters to avoid losing the valuable knowledge the model has already acquired.
In addition to these hurdles, another scenario where data can be jeopardized is during the process of compression. This even applies to quite simple actions, like when you want to compress PDF files, but thankfully these kinds of occurrences can be prevented with accurate alterations.
In the context of machine learning, ensuring the completeness and quality of data even when undergoing compression for storage or transmission is vital to developing a reliable model.
Transfer learning, with its reliance on pre-trained models, further highlights the need for careful management of data resources to prevent loss of information, ensuring that every piece of data is used to its fullest potential in the training and application phases.
Balancing the retention of learned features with the adaptation to new tasks is a delicate process that necessitates a deep understanding of both the model and the data at hand.
The horizon of transfer learning is constantly expanding, with research pushing the boundaries of what’s possible.
One exciting avenue here is the development of more universal models that can be applied across a broader range of tasks with minimal adjustments needed.
Another area of exploration is the improvement of algorithms for transferring knowledge between vastly different domains, enhancing the flexibility of transfer learning.
There’s also a growing interest in automating the process of selecting and fine-tuning pre-trained models for specific tasks, which could further lower the barrier to entry for utilizing advanced machine learning techniques.
These advancements promise to make transfer learning even more accessible and effective, opening up new possibilities for its application in fields where data is scarce or hard to collect.
The beauty of transfer learning lies in its adaptability that applies across all kinds of different domains.
From healthcare, where it can help diagnose diseases with limited patient data, to robotics, where it accelerates the learning of new tasks without extensive training, the potential applications are vast.
In the field of natural language processing, transfer learning has enabled significant advancements in language models with comparatively small datasets.
This adaptability doesn’t just showcase the efficiency of transfer learning, it highlights its potential to democratize access to advanced machine learning techniques to allow smaller organizations and researchers to undertake projects that were previously beyond their reach due to data limitations.
Even if it’s a Django platform, you can leverage transfer learning to enhance your application’s capabilities without starting from scratch all over again.
Transfer learning transcends the boundaries of specific programming languages or frameworks, making it possible to apply advanced machine learning models to projects developed in diverse environments.
Transfer learning is not just about overcoming data scarcity; it’s also a testament to efficiency and resource optimization in machine learning.
By building on the knowledge from pre-trained models, researchers and developers can achieve significant results with less computational power and time.
This efficiency is particularly important in scenarios where resources are limited, whether it’s in terms of data, computational capabilities, or both.
Since 43% of all websites use WordPress as their CMS, this is a great testing ground for ML models specializing in, let’s say, web scraping or comparing different types of content for contextual and linguistic differences.
This underscores the practical benefits of transfer learning in real-world scenarios, where access to large-scale, domain-specific data might be limited. Transfer learning also encourages the reuse of existing models, aligning with sustainable practices by reducing the need for energy-intensive training from scratch.
The approach exemplifies how strategic resource use can lead to substantial advancements in machine learning, making sophisticated models more accessible and environmentally friendly.
As we conclude our exploration of transfer learning, it’s evident that this technique is significantly changing machine learning as we know it, particularly for projects grappling with limited data resources.
Transfer learning allows for the effective use of pre-trained models, enabling both small and large-scale projects to achieve remarkable outcomes without the need for extensive datasets or computational resources.
Looking ahead, the potential for transfer learning is vast and varied, and the prospect of making machine learning projects more feasible and less resource-intensive is not just promising; it’s already becoming a reality.
This shift towards more accessible and efficient machine learning practices holds the potential to spur innovation across numerous fields, from healthcare to environmental protection.
Transfer learning is democratizing machine learning, making advanced techniques available to a far broader audience than ever before.
Nahla Davies is a software developer and tech writer. Before devoting her work full time to technical writing, she managed—among other intriguing things—to serve as a lead programmer at an Inc. 5,000 experiential branding organization whose clients include Samsung, Time Warner, Netflix, and Sony.