Image by Author
Large Language Models (LLMs) are a new type of artificial intelligence that is trained on massive amounts of text data. Their main ability is to generate human-like text in response to a wide range of prompts and requests.
I bet you have already had some experience with popular LLM solutions like ChatGPT or Google Gemini.
But have you ever wondered how these powerful models deliver such lightning-fast responses?
The answer lies in a specialized field called LLMOps.
Before diving in, let’s try to visualize the importance of this field.
Imagine you’re having a conversation with a friend. The normal thing you would expect is that when you ask a question, they give you an answer right away, and the dialogue flows effortlessly.
Right?
This smooth exchange is what users expect as well when interacting with Large Language Models (LLMs). Imagine chatting with ChatGPT and having to wait for a of couple minutes every time we send a prompt, nobody would use it at all, at least I wouldn’t for sure.
This is why LLMs are aiming to achieve this conversation flow and effectiveness in their digital solutions with the LLMOps field. This guide aims to be your companion in your first steps in this brand-new domain.
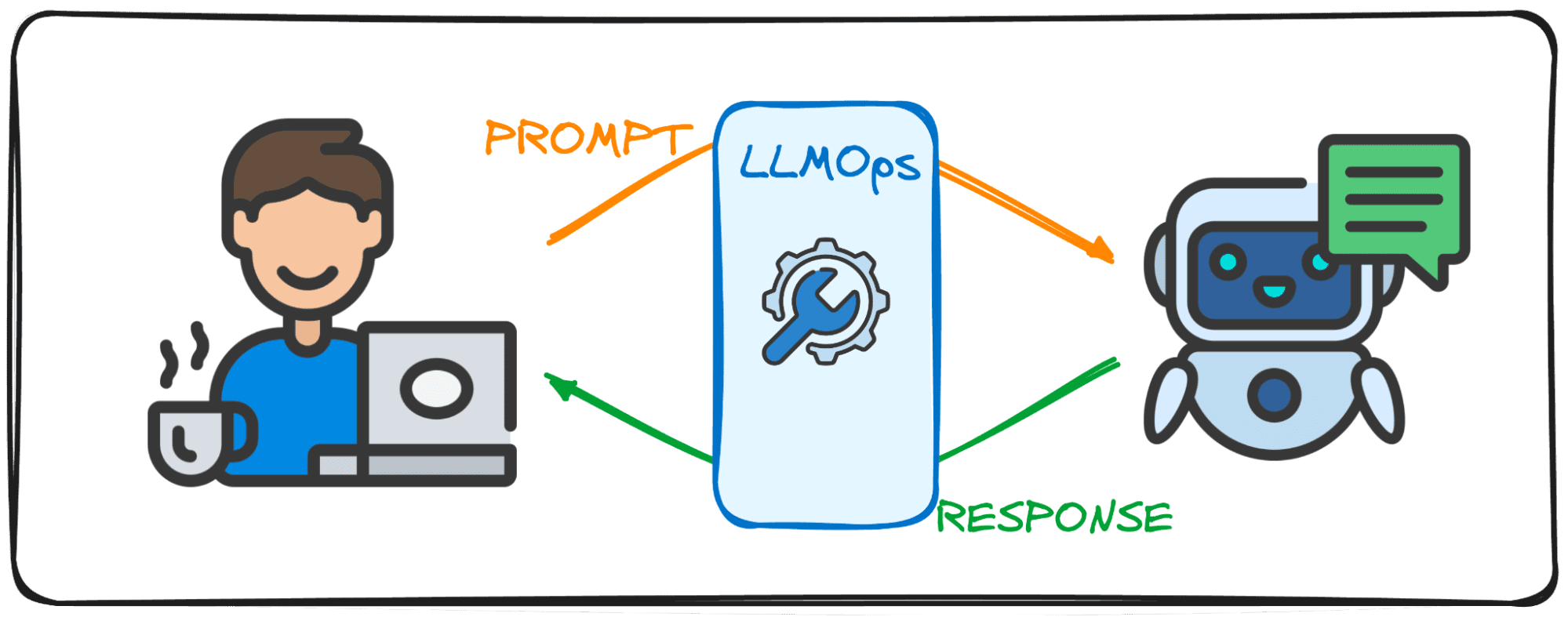
LLMOps, short for Large Language Model Operations, is the behind-the-scenes magic that ensures LLMs function efficiently and reliably. It represents an advancement from the familiar MLOps, specifically designed to address the unique challenges posed by LLMs.
While MLOps focuses on managing the lifecycle of general machine learning models, LLMOps deals specifically with the LLM-specific requirements.
When using models from entities like OpenAI or Anthropic through web interfaces or API, LLMOps work behind the scenes, making these models accessible as services. However, when deploying a model for a specialized application, LLMOps responsibility relies on us.
So think of it like a moderator taking care of a debate’s flow. Just like the moderator keeps the conversation running smoothly and aligned to the debate’s topic, always making sure there are no bad words and trying to avoid fake news, LLMOps ensures that LLMs operate at peak performance, delivering seamless user experiences and checking the safety of the output.
Creating applications with Large Language Models (LLMs) introduces challenges distinct from those seen with conventional machine learning. To navigate these, innovative management tools and methodologies have been crafted, giving rise to the LLMOps framework.
Here’s why LLMOps is crucial for the success of any LLM-powered application:
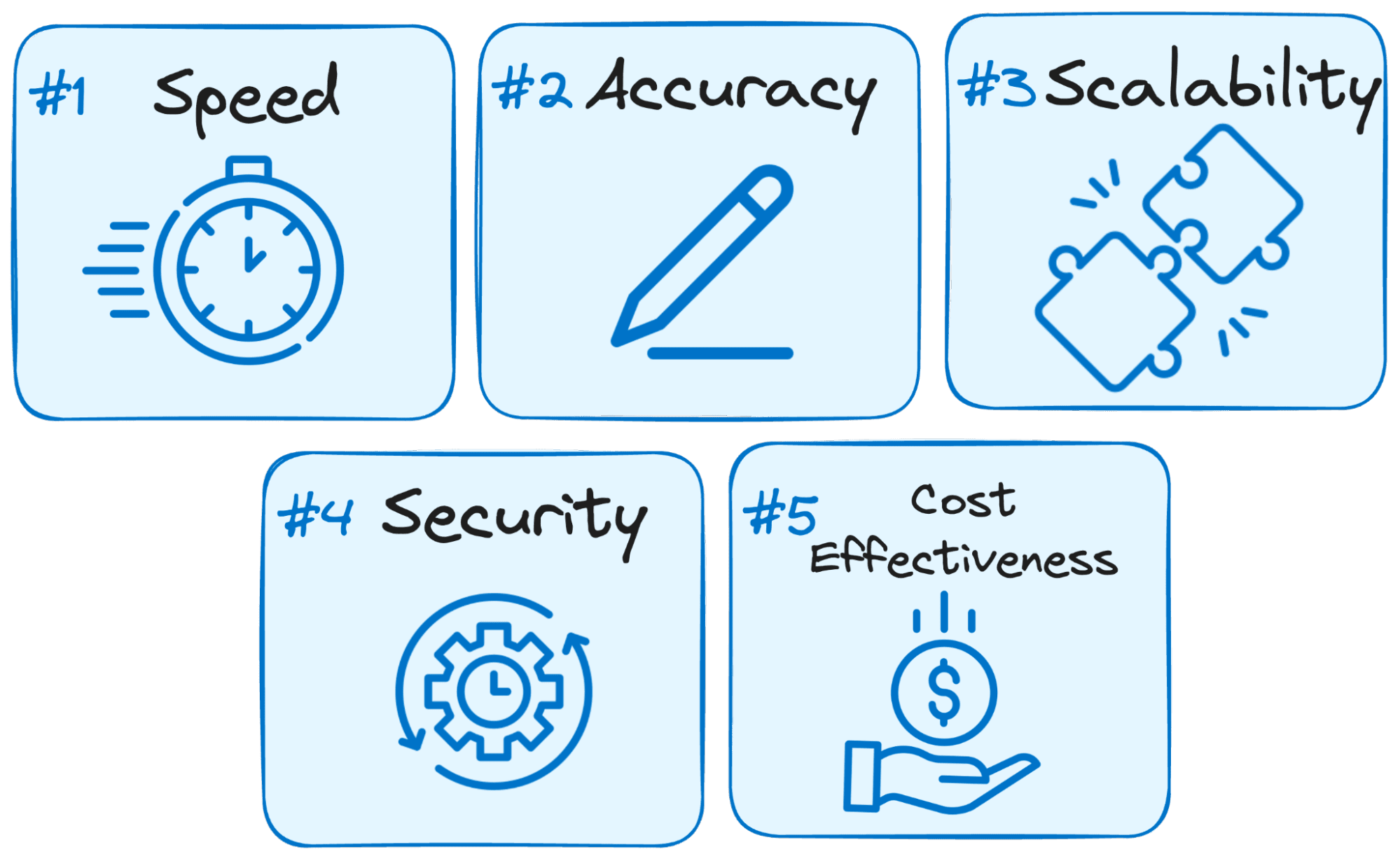
Image by Author
- Speed is Key: Users expect immediate responses when interacting with LLMs. LLMOps optimizes the process to minimize latency, ensuring you get answers within a reasonable timeframe.
- Accuracy Matters: LLMOps implements various checks and controls to guarantee the accuracy and relevance of the LLM’s responses.
- Scalability for Growth: As your LLM application gains traction, LLMOps helps you scale resources efficiently to handle increasing user loads.
- Security is Paramount: LLMOps safeguards the integrity of the LLM system and protects sensitive data by enforcing robust security measures.
- Cost-effectiveness: Operating LLMs can be financially demanding due to their significant resource requirements. LLMOps brings into play economical methods to maximize resource utilization efficiently, ensuring peak performance isn’t sacrificed.
LLMOps makes sure your prompt is ready for the LLM and its response comes back to you as fast as possible. However, this is not easy at all.
This process involves several steps, mainly 4, that can be observed in the image below.
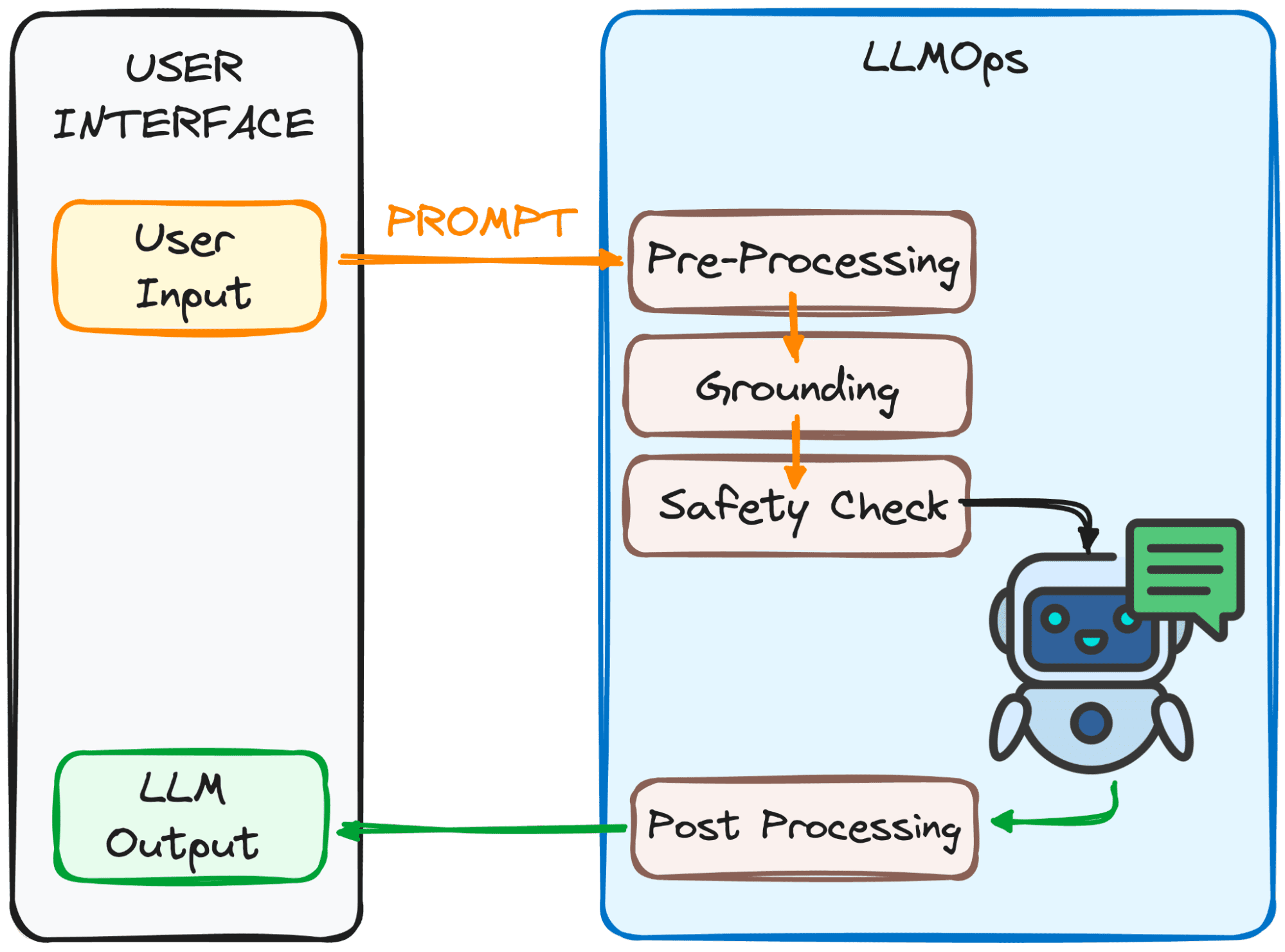
Image by Author
The goal of these steps?
To make the prompt clear and understandable for the model.
Here’s a breakdown of these steps:
1. Pre-processing
The prompt goes through a first processing step. First, it’s broken down into smaller pieces (tokens). Then, any typos or weird characters are cleaned up, and the text is formatted consistently.
Finally, the tokens are embedded into numerical data so the LLM understands.
2. Grounding
Before the model processes our prompt, we need to make sure that the model understands the bigger picture. This might involve referencing past conversations you’ve had with the LLM or using outside information.
Additionally, the system identifies important things mentioned in the prompt (like names or places) to make the response even more relevant.
3. Safety Check:
Just like having safety rules on set, LLMOps makes sure the prompt is used appropriately. The system checks for things like sensitive information or potentially offensive content.
Only after passing these checks is the prompt ready for the main act – the LLM!
Now we have our prompt ready to be processed by the LLM. However, its output needs to be analyzed and processed as well. So before you see it, there are a few more adjustments performed in the fourth step:
3. Post-Processing
Remember the code the prompt was converted into? The response needs to be translated back into human-readable text. Afterwards, the system polishes the response for grammar, style, and clarity.
All these steps happen seamlessly thanks to LLMOps, the invisible crew member ensuring a smooth LLM experience.
Impressive, right?
Here are some of the essential building blocks of a well-designed LLMOps setup:
- Choosing the Right LLM: With a vast array of LLM models available, LLMOps helps you select the one that best aligns with your specific needs and resources.
- Fine-Tuning for Specificity: LLMOps empowers you to fine-tune existing models or train your own, customizing them for your unique use case.
- Prompt Engineering: LLMOps equips you with techniques to craft effective prompts that guide the LLM toward the desired outcome.
- Deployment and Monitoring: LLMOps streamlines the deployment process and continuously monitors the LLM’s performance, ensuring optimal functionality.
- Security Safeguards: LLMOps prioritizes data security by implementing robust measures to protect sensitive information.
As LLM technology continues to evolve, LLMOps will play a critical role in the coming technological developments. Most part of the success of the latest popular solutions like ChatGPT or Google Gemini is their ability to not only answer any requests but also provide a good user experience.
This is why, by ensuring efficient, reliable, and secure operation, LLMOps will pave the way for even more innovative and transformative LLM applications across various industries that will arrive to even more people.
With a solid understanding of LLMOps, you’re well-equipped to take advantage of the power of these LLMs and create groundbreaking applications.
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is currently working in the data science field applied to human mobility. He is a part-time content creator focused on data science and technology. Josep writes on all things AI, covering the application of the ongoing explosion in the field.