Synthetic Data for Machine Learning
It’s no secret that supervised machine learning models need to be trained on high-quality labeled datasets. However, collecting enough high-quality labeled data can be a significant challenge, especially in situations where privacy and data availability are major concerns. Fortunately, this problem can be mitigated with synthetic data. Synthetic data is data that is artificially generated rather than collected from real-world events. This data can either augment real data or can be used in place of real data. It can be created in several ways including through the use of statistics, data augmentation/computer-generated imagery (CGI), or generative AI depending on the use case. In this post, we will go over:
- The Value of Synthetic Data
- Synthetic Data for Edge Cases
- How to Generate Synthetic Data
Problems with real data have led to many use cases for synthetic data, which you can check out below.
Privacy issues

Image by Google Research
Healthcare data is widely known to have privacy restrictions. For example, while incorporating electronic health records (EHR) into machine learning applications could enhance patient outcomes, doing so while adhering to patient privacy regulations like HIPAA is difficult. Even techniques to anonymize data aren’t perfect. In response, researchers at Google came up with EHR-Safe which is a framework for generating realistic and privacy-preserving synthetic EHR.
Safety Issues
Collecting real data can be dangerous. One of the core problems with robotic applications like self-driving cars is that they are physical applications of machine learning. An unsafe model can’t be deployed in the real world and causes a crash due to a lack of relevant data. Augmenting a dataset with synthetic data can help models avoid these problems.
Real data collection and labeling are often not scalable
Annotating medical images is critical for training machine learning models. However, each image should be labeled by expert clinicians, which is a time-consuming and expensive process that is often subject to strict privacy regulations. Synthetic data can address this by generating large volumes of labeled images without requiring extensive human annotation or compromising patient privacy.
Manual labeling of real data can sometimes be very hard if not impossible
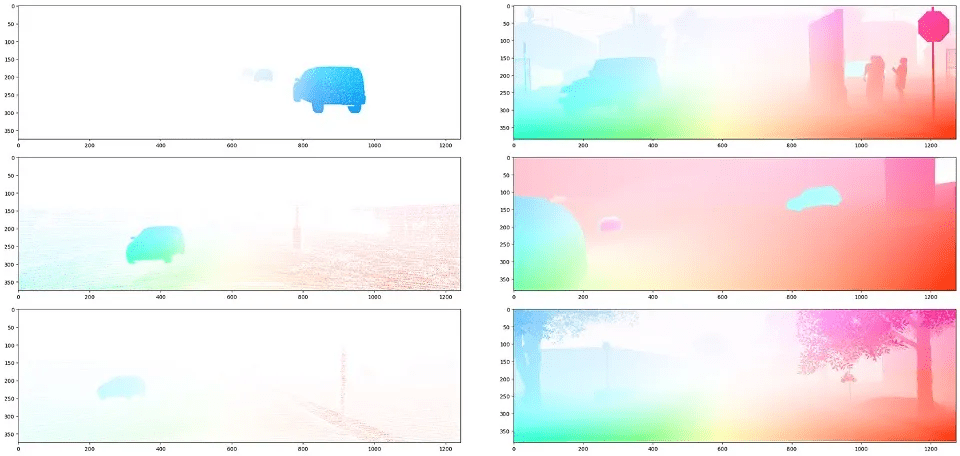
Optical flow labels of the sparse real-world data KITTI (left) and the synthetic data from Parallel Domain (right). The color indicates the direction and magnitude of flow. Image by author.
In self-driving, estimating per-pixel motion between video frames, also known as optical flow, is challenging with real-world data. Real data labeling can only be done using LiDAR information to estimate object motion, whether dynamic or static, from the autonomous vehicle’s trajectory. Because LiDAR scans are sparse, the very few public optical flow datasets are also sparse. This is one reason why some optical flow synthetic data has been shown to greatly improve performance on optical flow tasks.
A common use case of synthetic data is to deal with a lack of rare classes and edge cases in real datasets. Before generating synthetic data for this use case, please check out the tips below to consider what needs to be generated and how much of it is needed.
Identify your edge cases and rare classes
It is important to understand what edge cases are contained in a dataset. This could be rare diseases in medical images or usual animals and jaywalkers in self-driving. It is also important to consider what edge cases are NOT in a dataset. If a model needs to identify an edge case not present in the dataset, additional data collection or synthetic data generation might be necessary.
Verify the synthetic data is representative of the real-world
Synthetic data should represent real-world scenarios with minimal domain gaps which are differences between two distinct datasets (e.g., real and synthetic data). This can be done by manual inspection or by using a separate model trained on real data.
Make potential synthetic performance improvements quantifiable
A goal of supervised learning is to build a model that performs well on new data. This is why there are model validation procedures like train test split. When augmenting a real dataset with synthetic data, data might need to be balanced based on rare classes. For example, in self-driving applications, a machine learning practitioner might be interested in using synthetic data to focus on specific edge cases like jaywalkers. The original train test split may not have been split by the number of jaywalkers. In this case, it might make sense to move a lot of the existing jaywalker samples over to the test set to ensure that improvement by synthetic data is measurable.
Ensure all of your synthetic data is not just rare classes
A machine learning model should not learn that synthetic data is mostly rare classes and edge cases. Also, when more rare classes and edge cases are discovered, more synthetic data might need to be generated to account for this scenario.
A major strength of synthetic data is that more can always be generated. It also comes with the benefit of already being labeled. There are many ways to generate synthetic data and which one you choose depends on your use case.
Statistical methods
A common statistical method is to generate new data based on the distribution and variability of the original data set. Statistical methods work best when the dataset is relatively simple and the relationships between variables are well understood and can be defined mathematically. For example, if real data has a normal distribution like human heights, synthetic data can be created using the same mean and standard deviation of the original dataset.
Data augmentation/CGI
A common strategy to increase the diversity and volume of training data is by modifying existing data to create synthetic data. Data augmentation is widely used in image processing. This might mean flipping images, cropping them, or adjusting brightness. Just make sure that the data augmentation strategy makes sense for the project of interest. For example, for self-driving applications, rotating an image by 180 degrees so that the road is at the top of the image and the sky at the bottom doesn’t make sense.
Caption: Multiformer inference on an urban scene from the synthetic SHIFT dataset.
Rather than modifying existing data for self-driving applications, CGI can be used to precisely generate a wide variety of images or videos that might not be easily obtainable in the real-world. This can include rare or dangerous scenarios, specific lighting conditions, or types of vehicles. A couple of the drawbacks of this approach are that creating high-quality CGI requires significant computational resources. specialized software, and a skilled team.
Generative AI
A commonly used generative model to create synthetic data is Generative Adversarial Networks or GANs for short. GANs consist of two networks, a generator, and a discriminator, that are trained simultaneously. The generator creates new examples, and the discriminator attempts to differentiate between real and generated examples. The models learn together, with the generator improving its ability to create realistic data, and the discriminator becoming more skilled at detecting synthetic data. If you would like to try implementing a GAN with PyTorch, check out this TDS blog post.
These methods work well for complex datasets and can generate very realistic, high-quality data, However, as the image above shows, it is not always easy to control specific attributes like the color, text, or size of generated objects.
If a project doesn’t have enough high-quality and diverse real data, synthetic data might be an option. After all, more synthetic data can always be generated. This is a major difference between real and synthetic data as synthetic data is far easier to improve! If you have any questions or thoughts on this blog post, feel free to reach out in the comments below or through Twitter.
Michael Galarnyk is a Data Science Professional, and works in Product Marketing Content Lead at Parallel Domain.