The Essential Guide to SQL’s Execution Order
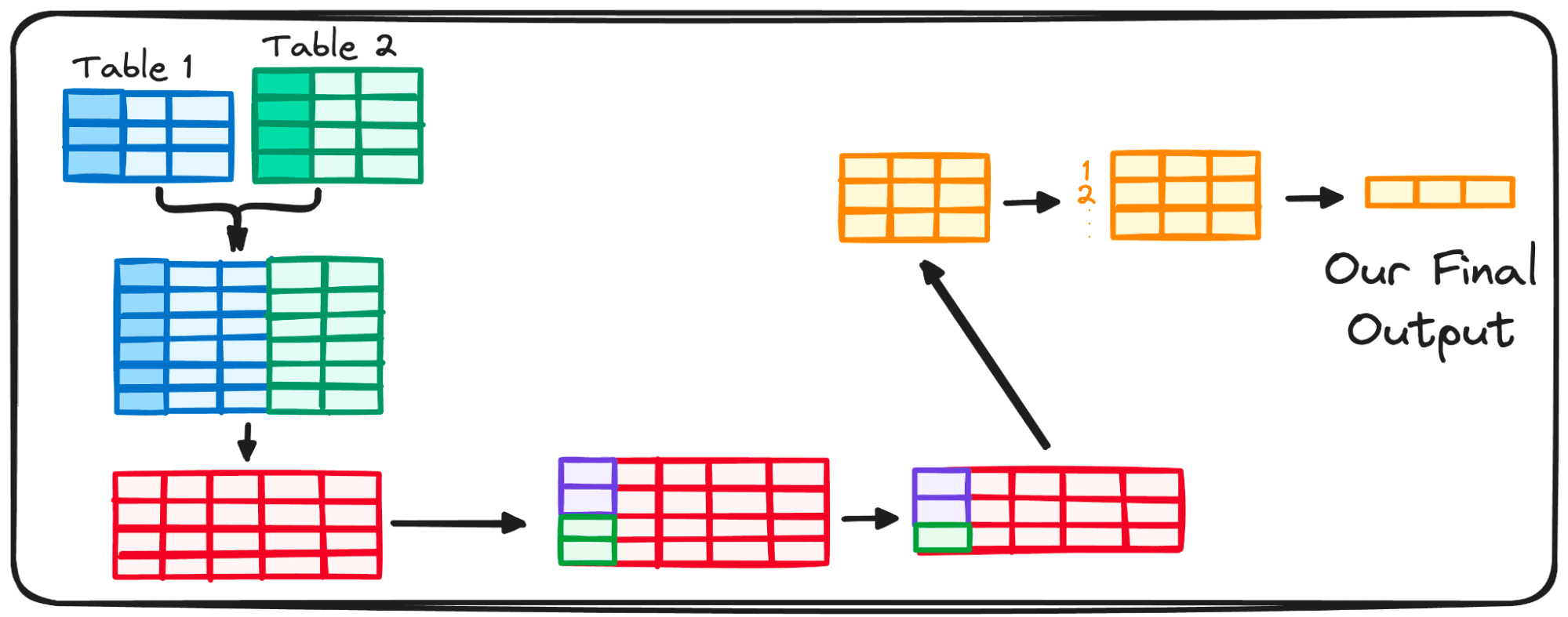
Image by Author
SQL has become a must-have language for any data professional.
Most of us use SQL in our daily work, and after writing many queries, we all get our own style and have our habits, both good and bad.
SQL is usually learned by use, and in most cases, people do not usually understand the logic behind it.
This is why, today, we’re diving into the intriguing world of SQL’s execution order, where the sequence of events can sometimes feel like a puzzle.
So, let’s fine-tune our understanding with a spotlight on the most common SQL query structure.
The first thing to understand is that SQL is a declarative programming language, which means that we specify the desired result but not what steps are required to achieve it.
This is quite the opposite of procedural languages, which define each step that needs to be performed to achieve our desired output.
But what does this mean?
It means that SQL requires commands to be coded in a certain syntax. Yet the order in which we write these commands doesn’t mirror the order in which SQL processes them.
Typically, a query unfolds with a structure like this:

Image by Author
Even though a person would read and code, following the previous structure, when considering how this code is executed, the order changes completely.
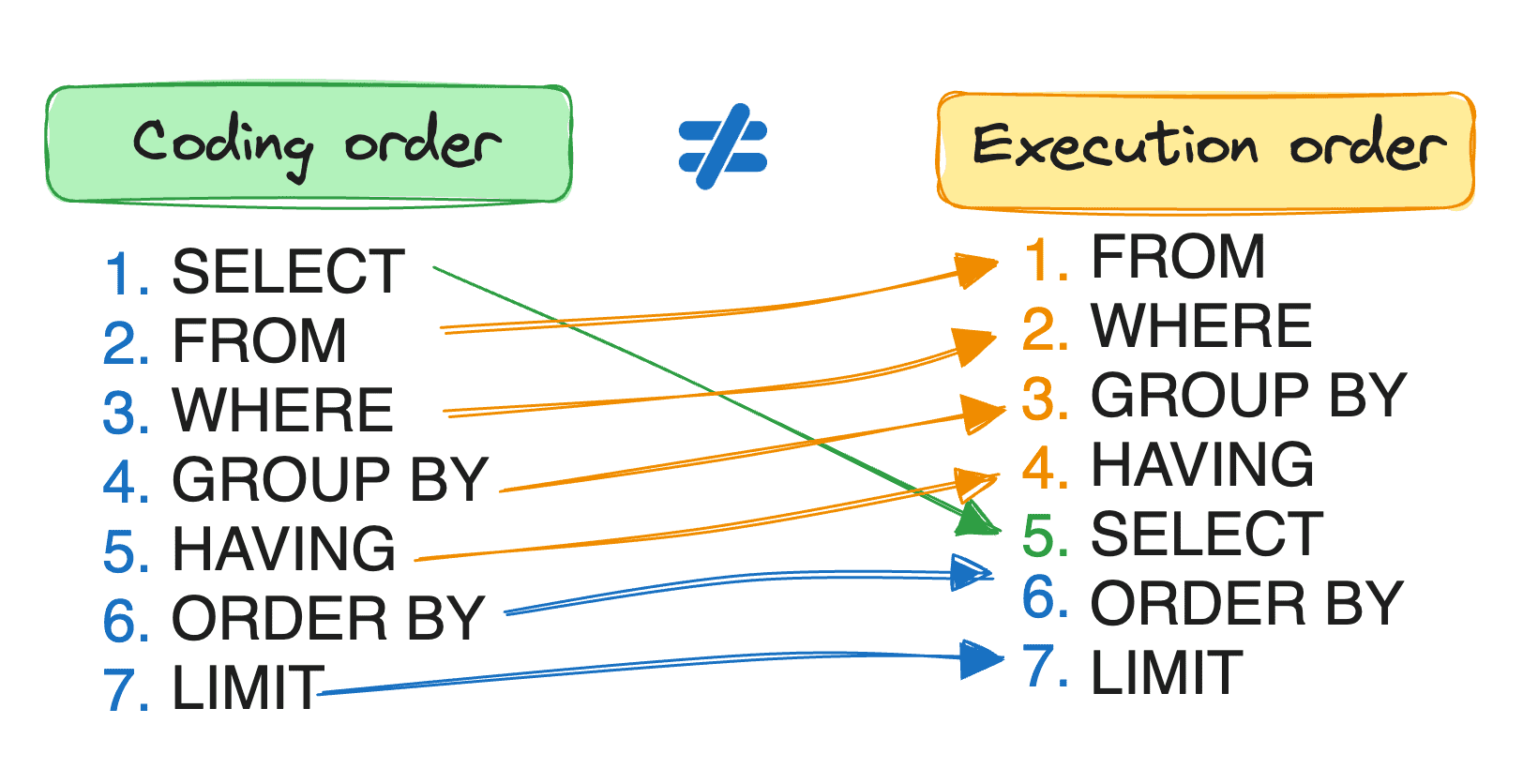
Image by Author
For instance, though written as the first command, the SELECT clause isn’t evaluated until almost the end.
To further understand this execution order, let’s go step by step and see what SQL does with every command we code.
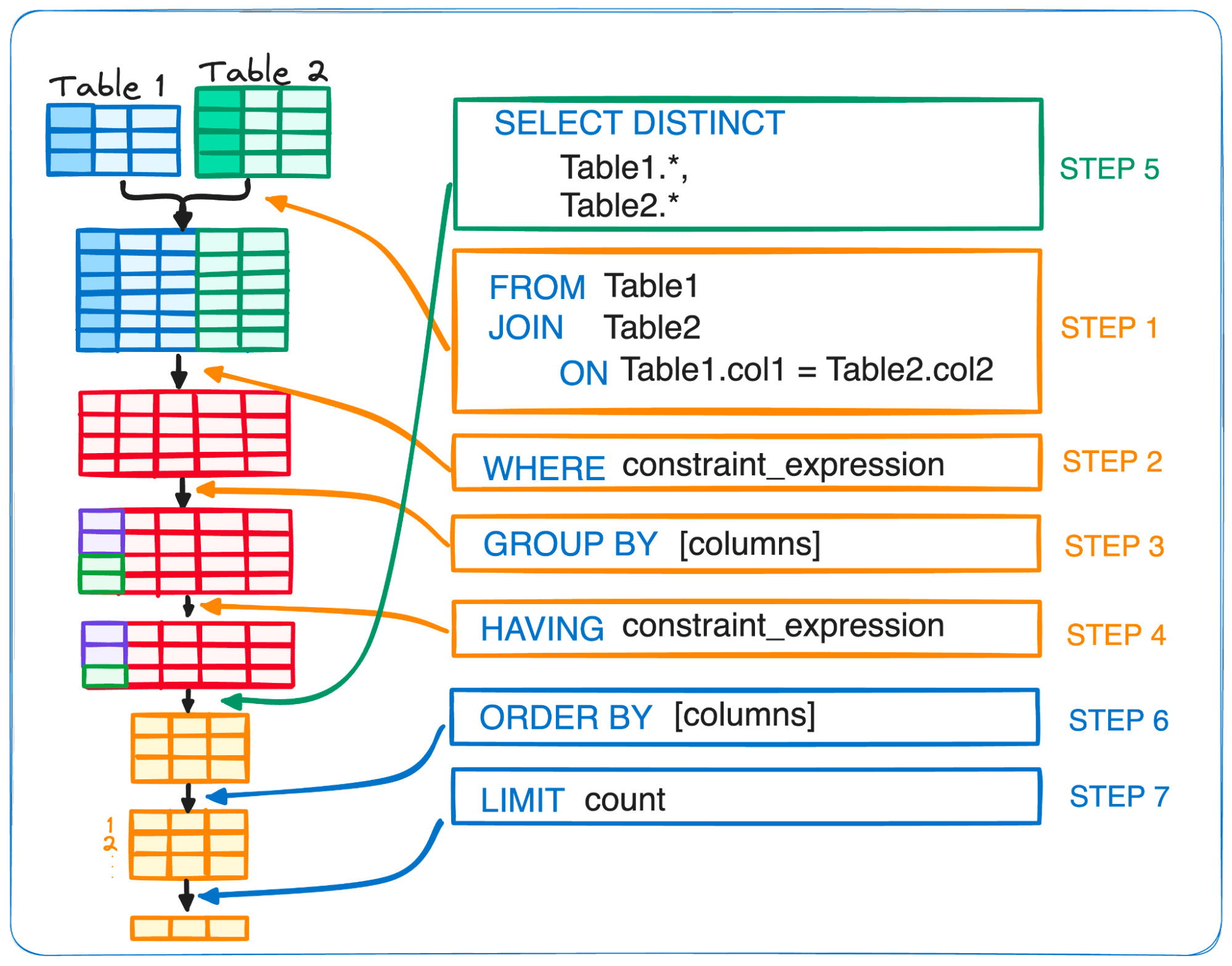
Image by Author
Step 1 – FROM and JOIN
The journey of a SQL query begins with the FROM clause, which points to the data’s origin. While straightforward queries might tap into just one table, the data we seek frequently is contained across several tables.
That’s where the JOIN command steps in, hand in hand with FROM, to merge together the data strands.
This pairing always takes the lead, setting the stage by pinpointing the data that will play a role in our query.
Step 2 – WHERE
Following the initial selection, the WHERE clause takes center stage.
Its primary role is to sift through the foundational table or the merged output from the join, ensuring only the rows that satisfy a specific condition are kept.
Step 3 – GROUP BY
The GROUP BY clause steps in to orchestrate the data, arranging it into clusters according to the values in one or more columns. This enables us to perform aggregations or summaries.
Consider it the maestro of data, reducing the multitude of variables to a singular value for each unique element or combination of elements.
This clause is the core command behind data aggregation, setting the stage for summary performances with functions like COUNT(), SUM(), MIN() and MAX() among others.
Step 4 – HAVING
The HAVING clause comes into play as a discerning filter, eliminating those groupings that fail to meet the set criteria.
Imagine it as a gatekeeper, ensuring that only the groups that align with our aggregate conditions are allowed to proceed. It steps in after the GROUP BY clause has done its part, allowing us to apply filters on the now aggregated data.
At this juncture, the database is already aware of the computed aggregations, which means we can use these aggregated values in subsequent statements.
To address the common misconception of why the WHERE clause can’t call aggregated variables while HAVE can:
It’s because WHERE takes the stage before the GROUP BY clause, at a time when individual data points haven’t yet been compiled into groups. On the other hand, HAVING takes place when the GROUP BY has already been computed.
Step 5 – SELECT
The SELECT clause defines the columns we want to keep in our table, along with any grouped or aggregated fields – that have been computed during the execution process.
Here, we can apply column aliases using the AS operator.
The SELECT command is usually used together with the DISTINCT, which allows us to discard any row with duplicate values in all columns marked as DISTINCT.
Step 6 – ORDER BY
With the foundational tasks completed, the ORDER BY clause steps in, orchestrating the sorted presentation of values in either ascending (ASC) or descending (DESC) order.
Picture this as the final act in our query.
We’ve gathered the data from our source tables, refined it with filters, crafted meaningful groups and summaries, and pinpointed the columns to showcase in our final output.
Step 7 – LIMIT
Finally, the LIMIT clause helps define the number of rows we want back.
It is particularly useful when dealing with large tables, especially during the development and testing stages.
Understanding the sequence of SQL’s execution order might seem trivial at the outset, especially when queries are yielding the correct results.
Why fuss over the mechanics if the engine runs fine, right?
Yet, for those diving into the deeper waters of complex queries, knowledge of this order isn’t just useful—it’s crucial.
Without this insight, troubleshooting becomes a maze of confusion, with errors lurking like all around. For adept debugging and smoother query crafting, a solid grasp of how SQL processes its clauses is indispensable. Two common mistakes are:
Mistake 1
A typical pitfall in SQL is the attempt to filter aggregated data using the WHERE clause—a misstep that leads to an error.
Image by Author
As we have already seen throughout this article, the WHERE clause is computed before the GROUP BY one, therefore, we cannot use aggregated values during the WHERE step.
Mistake 2
Referencing column aliases of aggregated values that have not been set yet. In this case, we cannot use an alias that has been defined in the very same SELECT, as the computation phase is the same.
Therefore, SQL is not aware of this new alias yet.

Image by Author
Understanding SQL’s execution order is crucial for data professionals to craft effective, efficient queries.
This insight allows one to anticipate query behavior, especially in complex datasets.
Mastering SQL involves moving beyond syntax and embracing its logic for strategic data manipulation.
The journey we have performed together, from the FROM clause to LIMIT, is a strategic blueprint for data handling and shaping information to fit specific needs.
Hope next time you are coding SQL, you keep this execution order in mind!
Josep Ferrer is an analytics engineer from Barcelona. He graduated in physics engineering and is currently working in the Data Science field applied to human mobility. He is a part-time content creator focused on data science and technology. You can contact him on LinkedIn, Twitter or Medium.